

Gastbeitrag: Was so alles Text ist, und wie man es untersucht
BLOG: Fischblog

Mein heutiger Gastautor ist Jürgen Hermes, wissenschaftlicher Mitarbeiter an der Sprachlichen Informationsverarbeitung am Institut für Linguistik der Universität zu Köln und meiner Twittergemeinde als @spinfoCL bekannt.

Seine dieses Jahr erschienene Dissertation “Textprozessierung – Design und Applikation” behandelt die theoretischen Grundlagen, die Architektur und die beispielhafte Anwendung eines Software-Labors für Wissenschaftler, die mit textuellen Rohdaten arbeiten. Momentan werkeln er und seine Kolleg[inn]en am Lehrstuhl an der weiteren Ausstattung dieser Laborinfrastruktur.
Jürgen Hermes bloggt unter http://texperimentales.hypotheses.org regelmäßig über sein Fachgebiet
Geisteswissenschaftler haben unter Naturwissenschaftlern nicht immer den besten Ruf. Das ist jedenfalls mein Eindruck, wenn ich den Konversationen in meiner Twitter-Timeline folge, in der sich eine Menge Wissenschaftsblogger aus dem naturwissenschaftlichen Spektrum herumtreiben. Vor allem während der Diskussion um diverse mal mehr, mal weniger plagiierte Arbeiten zur Erlangung der Doktorwürde wurde oft darauf verwiesen, dass es sich um ein geisteswissenschaftliches Problem handle, welches sich auf der Fragilität und der fragwürdigen Methoden dieser Wissenschaften gründet.1 Gerade aufgrund dieser Vorurteile halte ich es für eine wirklich gute Idee, dass der Fischblog uns Geisteswissenschaftlern die Möglichkeit gibt, unsere Gegenstandsbereiche und Methoden einem naturwissenschaftlichen Leserkreis vorzustellen.
Computerlinguistik als Geisteswissenschaft
Ich kann hier selbstredend nicht für die Geisteswissenschaften im Gesamten sprechen, wahrscheinlich lässt sich aufgrund der Heterogenität der Themenbereiche wohl auch kaum jemand finden, der dazu in der Lage wäre. Mir ist auch schon häufiger entgegengehalten worden, dass wir als Computerlinguisten2 überhaupt keine Geisteswissenschaftler wären. Tatächlich befindet sich unser Forschungsbereich an der Schnittstelle zwischen der ingenieurwissenschaftlich orientierten Informatik und der traditionell an der Philosophischen Fakultät beheimateten Sprachwissenschaft, so dass dieser Vorwurf zwar nicht völlig abgestritten werden kann, allenfalls aber auch nur zum Teil zutrifft.
Die Computerlinguistik beschäftigt sich grob gesagt mit allen denkbaren Schnittstellen zwischen natürlichen Sprachen und künstlichen Rechnersystemen. Das ist immernoch ein relativ weit gefächertes Gebiet – darunter fällt die Entwicklung von Modellen für die Verarbeitung (Analyse oder Generierung) natürlichsprachlicher Äußerungen genauso wie die Erschließung von Information aus derartigen Äußerungen sowie die computergestütze Ermittlung des diesen Äußerungen zugrundeliegenden Sprach-Systems.

Na gut, so kann man es auch sehen. Das, was wir machen, bezeichne ich daher auch lieber mit “Natural Language Processing”.
Die Suche nach einem solchen System, das natürlichen Sprachen zugrundeliegt, ist eine der zentralen Fragestellungen der gesamten Linguistik: Weshalb sind wir in der Lage, in einer relativ frühen Entwicklungsphase ein derart komplexes System zu erlernen und anzuwenden? Wie ist dieses System geartet? Ist es überhaupt exakt (über Symbole und Regeln) beschreibbar oder ist es lediglich auf einer speziellen Hardware (wie unserem Gehirn) repräsentierbar? Und wie können wir diesem System auf die Spur kommen?
Alle diese Fragen sind in der Linguistik nicht abschließend geklärt – tatsächlich existieren eine Reihe verschiedener Theorie-Schulen, die ihre Modelle von Aufbau, Erwerb und Ermittlung des Sprachsystems auf äußerst unterschiedlichen Prämissen gründen. Verschiedene Forschungsströmungen mögen in den Naturwissenschaften auch nebeneinander existieren, so gab es ja immer wieder alternative Modelle zum Standardmodell der Teilchenphysik, das aber dessen ungeachtet den Status des vorherrschenden Erklärungsmodells behalten hat (und das offensichtlich – soweit ich das verstanden habe – durch die neuesten Ergebnisse am CERN weitere Unterstützung findet). Ein solches Standardmodell gibt es meiner Einschätzung nach für die Linguistik nicht.3
Um nur eine Frage, über die Uneinigkeit besteht, herauszugreifen: Kann man die Eigenschaften eines sprachlichen Systems ermitteln, indem man tatsächlich existierende Sprachdaten auswertet? Oder kann man der Funktionsweise natürlicher Sprachen nur auf die Spur kommen, indem man sein eigenes Sprachgefühl befragt (das nennt man dann Introspektion eines idealisierten Sprecher/Hörers, eigentlich: eines Sprachwissenschaftlers)?
Die letztere Ansicht, die vor allem von der vom einflussreichen Linguisten Noam Chomsky ins Leben gerufenen Generativen Grammatik vertreten wird, ist des öfteren Ziel von Spott, etwa in der von Charles Fillmore4 entworfenen Karikatur eines Armchair Linguist: “He sits in a deep soft comfortable armchair, with eyes closed and his hands clasped behind his head. Once in a while, he opens his eyes, sits up abruptly shouting, ‘Wow, what a new fact!’, grabs his pencil, and writes something down. Then he paces arround for a few hours in the excitement of having come still closer to knowing what language is really like.” Oder, wie Mc Enery und Wilson5 es ausdrücken (wobei sie sich von der Sichtweise halbherzig distanzieren, indem sie sie als “Folklore” kennzeichnen): “Corpus Linguists study real language, other linguists just sit at their coffee table and think of wild and impossible sentences.” Ich will hier gar nicht tief in den Grabenkampf einsteigen, im Fall der Computerlinguistik (zumindest dem Teil, der ins Englische mit Natural Language Processing übersetzt wird) herrscht zumindest momentan die Meinung vor, dass es eine gute Idee ist, Sprachmodelle über große Sprachdatensammlungen (Korpora) zu bilden.6
Texte als Repräsentationsform
Sprach-Korpora können in ganz unterschiedlicher Form erhoben werden.7 Die ursprüngliche sprachliche Kommunikationsform basiert auf audiovisuellen Signalen (Unterstützung der Rede durch Mimik und Gestik); seit Erfindung der Schrift können sprachliche Äußerungen aber auch in Texten konserviert werden. Texte sind zugegebenermaßen nur eine mögliche Repräsentationsform von natürlichsprachlichen Äußerungen, die darüber hinaus auch nur einen Ausschnitt der Eigenschaften des Untersuchungsgegenstands aufnehmen können. Aber Texte – zumindest die gedruckten – bieten den enormen Vorteil, dass sie aus Sequenzen diskreter Einheiten eines definierten Alphabets bestehen.8 Als solche sind sie extrem effizient speicherbar, indizierbar, analysierbar und weiter verarbeitbar. Betrachtet man Texte als seinen Untersuchungsgegenstand, so bekommt man dessen Virtualisierung quasi geschenkt, das Untersuchungsobjekt lässt sich verlustfrei dort repräsentieren, wo es auch analysiert wird. Anders ausgedrückt: Man kann den Algorithmus direkt über die Originaldaten laufen lassen.
Das Spannende an einem derart generalisierten Textbegriff ist, dass er nicht nur für Teilbereiche der Geisteswissenschaften genutzt werden kann, sondern dass er sich auch auf Untersuchungsobjekte naturwissenschaftliche Bereiche ausdehnen lässt. So kann man ja auch das menschliche Erbgut auf der Desoxyribonucleinsäure (DNA) als Folge von Basen auf einem Zucker-Phosphat-Band ansehen, die durch vier verschiedene Buchstaben repräsentiert werden können und damit einen Text darstellen. Selbst mir als Nicht-Biologen ist natürlich klar, dass durch diese eindimensionale Darstellung lediglich die Primärstruktur der DNA abgebildet wird und sämtliche Faltungen im Raum sowie die Eigenschaften der DNA-einbettenden Zelle vernachlässigt werden. Dennoch hat der Bereich der Bioinformatik durch die Analyse genau dieser Repräsentation teilweise bemerkenswerte Beiträge zur Erbgutforschung geliefert.

Texte, als Sequenzen diskreter Einheiten verstanden, können alles Mögliche sein.
Vor allem im Zuge der Etablierung der Bioinformatik wurden Verfahren entwickelt, die effizient mit sehr großen Textmengen umgehen können, so bspw. unterschiedliche Ansätze zum Alignment von Sequenzen oder Suffixbäume und -arrays, die ein großes Textkorpus in einer Weise vorprozessieren, die eine effiziente Suche nach Teil-Texten möglich macht. Diese Verfahren können auch im Bereich der Verarbeitung natürlicher Sprachen genutzt werden, wie etwa der Linguist Martin Kay6 zeigt. Auch in umgekehrter Richtung wurden bereits Methoden transferiert, etwa als der zur Erkennung von Spam-Emails entwickelte Teiresias-Algorithmus auf die Ermittlung potentieller Epitopen in Proteinen eingesetzt wurde.7 Ein generalisierter Textbegriff ist dabei eine wichtige Voraussetzung, um Verfahren und Methoden in dieser Art zwischen verschiedenen Wissenschaftsdomänen auszutauschen. In meiner Dissertation habe ich zum Beispiel eine Reihe von Verfahren genutzt, um chiffrierte Texte miteinander zu vergleichen, darunter auch eigentlich für die Analyse genomischer Daten entwickelte Methoden wie Suffix- und Schlüsselwortbäume sowie das Random Walk Modell.
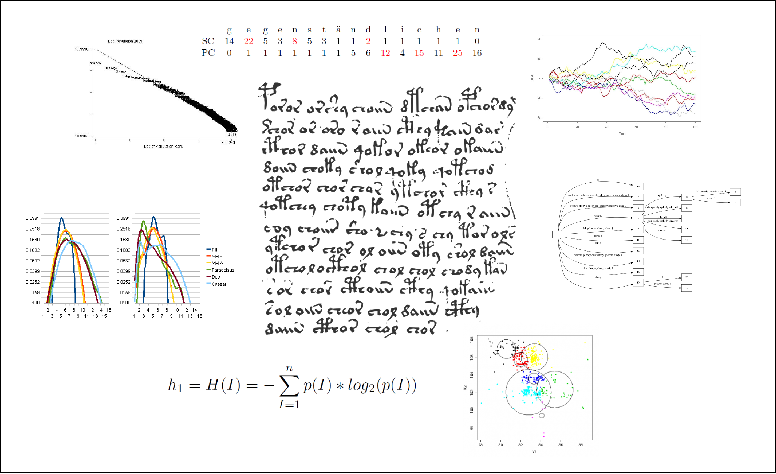
Methodeninventar verschiedener Wissenschaftsdomänen, anwendbar auf unterschiedliche Untersuchungsobjekte.
Dass man überhaupt Verfahren auf so verschiedene Untersuchungsobjekte anwenden kann, liegt nicht nur daran, dass sie in einer vergleichbaren Repräsentationsform vorliegen. Im Grunde wird nämlich auch nach dem Gleichen gesucht – nach Mustern (Wiederholungen, Variationen etc.). Verfahren zur Aufdeckung dieser Muster können deshalb die Grenzen zwischen verschiedenen Wissenschaftsbereichen überwinden – wobei die Interpretation der detektierten Muster (die Zuordnung von Bedeutung) – in der Regel innerhalb der der Einzelwissenschaften erfolgt und nur schwer zwischen ihnen übertragbar ist.
Vollständige Reproduzierbarkeit
Auf eine gewisse Weise ist der Ansatz des wissenschaftlichen Methodentransfers etwas, was man auch als Open Science bezeichnen könnte, insofern damit Grenzen zwischen bislang entkoppelten Forschungsbereichen überwunden werden können. Bisher werden unter dem Begriff Open Science ja v.a. neue Möglichkeiten des Zugriffs auf Veröffentlichungen (Open Access) von Forschungsergebnissen und Primärdaten (Open Data) verstanden. In meiner Dissertation zeige ich auf, dass man – zumindest bei der Analyse von text-repräsentierbaren Untersuchungsobjekten – noch mehr Transparenz in die eigene wissenschaftliche Arbeit bringen kann: Da sich sowohl die Rohdaten, wie auch die darauf angewendeten Verfahren vollständig in silico befinden, ist es möglich, die Analysen, die man durchführt, exakt zu dokumentieren. Voraussetzung dafür ist eine Art virtuelles Labor, in dem die zu analysierenden Daten vorgehalten werden und unterschiedliche Verfahren implementiert wurden, die auf diesen Daten angewendet werden können.
Ein solches virtuelles Labor sollte ein Laborbuch anbieten, in dem die Experiment-Aufbauten und -Ergebnisse lückenlos dokumentiert werden und das automatisch erzeugt wird. Wenn zusätzlich ein geeigneter Import- und Export-Mechanismus für derart dokumentierte Experimente geschaffen wird, ist es möglich, die eigene wissenschaftliche Arbeit in einer tatsächlich reproduzierbaren Form weiterzugeben.
Bedingung dafür ist natürlich, dass die an der Analyse beteiligte Software für den Reproduzenten freigegeben ist. Über die Frage, ob dies in Zukunft zum Standard für wissenschaftliches Arbeiten gehören sollte, gab es letztens auch eine Diskussion im Blog von Florian Freistätter, in der allerdings keine Einigkeit erzielt werden konnte. Sofern ich das verstanden habe, ist das Hauptargument gegen die Freigabe von Software die Tatsache, dass es sich nicht um echte Reproduktion von Ergebnissen handelt, weil zwangsläufig das gleiche herauskommt, wenn man dieselbe Software auf denselben Daten laufen lässt. Vielmehr sei es völlig ausreichend, den Algorithmus (prosaisch/formal) zu beschreiben, der dann in einer Neu-Implementation die erzielten Ergebnisse bestätigen sollte. Ich kann hier wieder nur für mein Fachgebiet sprechen, aber bei der Prozessierung von Sprachdaten ist es – aufgrund der Vielzahl von Prozessierungsschritten – unmöglich, diese alle exakt zu dokumentierten. Sehr anschaulich wird das in einer Parabel vom Zigglebottom Tagger, die Tod Pedersen in seinem wirklich sehr lesenswerten Artikel “Empiricisim Is Not a Matter of Faith” dargelegt. So können bspw. schon geringe Abweichungen im verwendeten Wortmodell (wie behandelt man Bindestrich-Wörter, Abk. usw.) Ergebnisse nachgelagerter Prozessierungsschritte verändern und möglicherweise die Beurteilung der Güte von Verfahren beeinflussen. Außerdem ermöglicht die Weitergabe von konfigurierbaren Softwarekomponenten, dass andere Wissenschaftler direkt an die eigenen Forschungen anknüpfen können, indem sie jene z.B. auf einen anderen Datenpool oder mit abweichender Zusammenstellung und/oder Konfiguration anwenden.
Ein Labor für Textprozessierer
An meinem Lehrstuhl haben wir (im Zuge zweier Promotionen) ein System entwickelt, das ein solches Labor für Textprozessierer simuliert. Wir haben es nach dem großen Erfinder Nicola Tesla8 benannt, auch weil sich dadurch das schöne Akronym für Text Engineering Software Laboratory ergibt. Tesla verwaltet Rohdaten (Texte) und Werkzeuge (kombinierbare und konfigurierbare Softwarekomponenten) und erlaubt es, mittels eines graphischen Editors Experimente aus diesen Komponenten zusammenzustellen. Sobald das Experiment ausgeführt wird, werden alle relevanten Informationen (welche Textdaten und Werkzeuge wurden verwendet, wie sind letztere konfiguriert) in einer exportierbaren Datei gespeichert. Diese Datei kann z.B. über die Plattform MyExperiment veröffentlicht und dann in jede andere Tesla-Instanz importiert werden. Damit steht es jedem interessierten Wissenschaftler frei, die Ergebnisse von Experimenten zu reproduzieren, den Code und die Konfiguration der Softwarekomponenten zu studieren und diese evtl. durch seine eigenen Vorstellungen zu modifizieren.
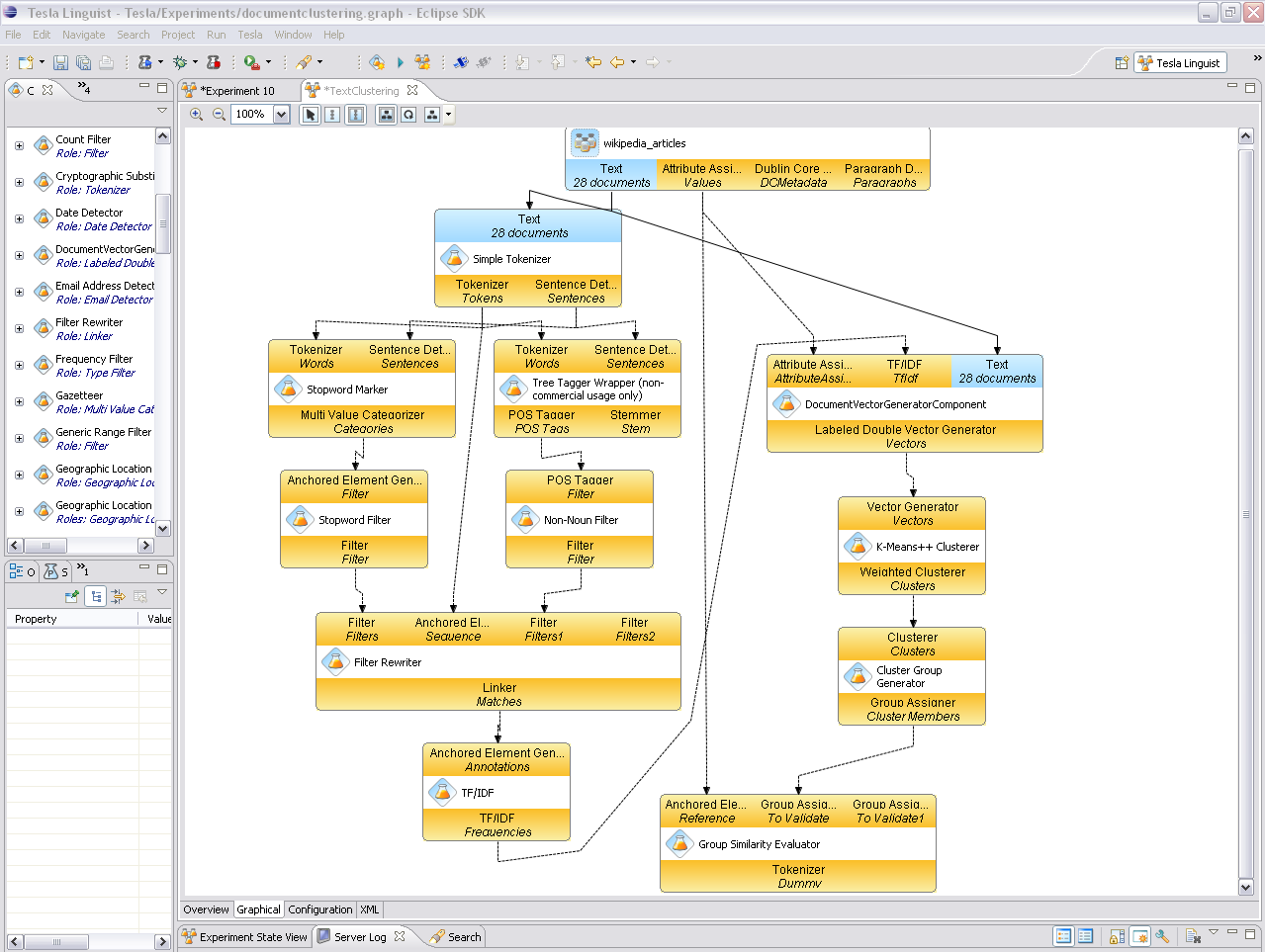
Wir sehen Tesla als unseren Beitrag zu einer neuen Forschungslandschaft, die man eben auch als Open Science bezeichnen kann – einerseits können Wissenschaftler verschiedener Forschungsbereiche von den bereits implementierten Verfahren anderer Wissenschaftler profitieren, andererseits wird es mit Systemen wie Tesla und Plattformen wie MyExperiment jetzt möglich, nicht nur Rohdaten und Ergebnisse, sondern darüber hinaus auch die Experimente selbst zu veröffentlichen und damit zur Begutachtung, Überprüfung und Modifikation freizugeben. Uns scheint das ein erstrebenswerter Ansatz zu sein.
—
1 Man muss allerdings dazu anmerken, dass es sich bei einem Großteil der Fälle um Gebiete handelt, die eher den Gesellschafts- als den Geisteswissenschaften zugerechnet werden. So mancher Naturwissenschaftler scheint da aber keinen Unterschied zu machen.
2 Studiert habe ich das Fach Informationsverarbeitung, das sich als angewandte Informatik für die Geisteswissenschaften versteht und dessen Zweig Sprachliche Informationsverarbeitung (das ist auch der Lehrstuhl, an dem ich noch immer beschäftigt bin) im Groben dem Fachbereich Computerlinguistik entspricht.
3 Mein vorübergehender Blogherbergsvater Lars Fischer wies mich darauf hin, dass in den Naturwissenschaften Modelle prinzipiell durch Experimente unterscheidbar und damit widerlegbar sind. Widersprechen sich zwei Modelle, sei eines definitiv falsch. In der Linguistik dürfte das nicht grundlegend anders sein (dem kritischen Rationalismus haben sich so gut wie alle linguistischen Schulen verschrieben) – problematisch ist das Design eines Experiments, das von allen Beteiligten anerkannt wird und dessen Ausgang auch eindeutig interpretierbar ist. Das liegt daran, dass wir es bei Sprache mit etwas wenig handfestem zu tun haben, das irgendwie Output unseres Geistes ist und dessen Grundlagen in diesem auf irgendeine Art codiert wurden. Wie diese Codierung vor sich ging und wie genau das Ergebnis aussieht, ist aus ethischen Gründen schwer kontrolliert experimentell zu untersuchen. Eine Möglichkeit, ein wenig mehr über das menschliche Sprachsystem zu erfahren, besteht im Studium von Patienten, die an Aphasien unterschiedlicher Art leiden. Hintergrund ist der Gedanke, dass man durch Analysen der Nicht-Norm Aussagen über die Norm tätigen kann. Leider funktioniert das nicht für alle Bereiche der Sprachwissenschaft.
4 Charles Fillmore “‘Corpus linguistics’ vs. ‘Computer-aided armchair linguistics'” Text bei Google Books
5 Tony McEnery & Andrew Wilson: “Corpus Linguistics” Buch bei Google Books
6 Hier kam bei Lars die Frage auf, wie denn Methoden in der Geisteswissenschaft evaluiert werden. Ich ziehe mich hier lieber wieder auf mein Gebiet, die Computerlinguistik zurück, wo man bei der Beurteilung von sprachtechnologischen Anwendungen so etwas wie einen Gold Standard benötigt und die eigene Anwendung danach bewertet, wie nahe sie diesem Gold Standard kommt. Das geschieht oft über die Berechnung von Precision (kurz: Wieviele Ergebnisse von meiner Anwendung finden sich auch im Gold Standard) und Recall (kurz: Wieviel vom Gold Standard hat meine Anwendung geliefert). Aus beiden Werten kann man dann das symmetrische Mittel bilden (was dann F-Score genannt wird) und mit den F-Scores anderer Anwendungen, die auf anderen Methoden beruhen, vergleichen.
7 Die Zusammenstellung repräsentativer Korpora ist eine Wissenschaft für sich. Will man bspw. den Spracherwerb von Kindern untersuchen, macht es wohl keinen Sinn, dafür Fachbuchtexte auszuwerten – viel eher würde man da wohl mündliche Kommunikation mit Kleinkindern auswerten. Viel Zeit und Geld wurde für den Aufbau von großen Nationalkorpora verwendet, von denen das British National Corpus (BNC) wohl das bekannteste ist. Das Problem ist dabei immer, dass Sprache nicht abgeschlossen ist und das es sehr schwer ist, irgend etwas als repräsentativ für anderes festzulegen. Das Urheberrecht in Deutschland tut sein übriges dazu – so darf man sich nicht einfach ein Korpus aus Zeitungstexten zusammensuchen oder Webseiten auslesen und speichern. Schwieriges Thema, das nach einem eigenen Beitrag ruft – im besten Fall von jemandem, der sich mit der Materie besser auskennt.
8 Das ist zugegebenermaßen eine – ja nach Betrachtungsweise – sehr enge bzw. sehr weite Textdefinition, die keinem linguistischen oder editionsphilologischen Textbegriff entspricht. Dass sie dennoch zweckmäßig sein kann, wird hoffentlich durch die weiteren Ausführungen dargelegt.
9 Martin Kay: “Substring Alignment Using Suffix Trees” pdf
10 V. Jojic et al:”HLA-driven Optimization of an HIV Vaccine Immunogen” Abstract
11 Tesla steht hier unter der Eclipse Public Licence (Open Source) zum Download zur Verfügung. Dort findet sich auch die Dokumentation zum Projekt und Tutorials zur Benutzung der Software. Daneben habe ich in meinem Blog (der normalerweise bei der Plattform de.hypotheses untergebracht ist) eine Reihe von Beiträgen verfasst, die vielleicht dem ein oder anderen als Startpunkt dienen können, die eigene Forschung durch Tesla zu unterstützen.
Nachtrag: Geschlechtsneutralität
Ich bin kein Anhänger der Kirche des Generischen Maskulinums, mir ist die Verwendung von Formen, die auch wirklich beide Geschlechter ansprechen, nur noch nicht in Fleisch und Blut übergegangen. Statt Lars jetzt mit vielen Änderungswünschen zu nerven, bitte ich daher hier per Kommentar die [Geistes|Natur]wissenschaftlerinnen und die Wissenschaftsbloggerinnen, mir diesen Fauxpas zu verzeihen. Ich habe auch sie gemeint, nur oft vergessen, das vernünftig (geschlechtneutral) auszudrücken!
Die Computerlinguistik
… ist insofern wertvoll, weil sie im Web Anwendungen unterstützt. Suchmascheinen und ähnliche Dienste müssen aber nicht verstehen, was wirklich [1] gemeint ist, sondern was dem Suchenden helfen kann.
Dr. Webbaer, der hier nur interessierter Laie ist, aber Verbesserungen bei der Such-Algoritmik (sofern dieser Begriff “geht” 🙂 wohl bemerkt hat, kann hier teilweise folgen.
Die Linguistik, wir denken auch an einen hiesigen bemühten Bremer Linguisten, ist allerdings aus sich heraus problematisch, wenn es um über die Regeln Hinausgehendes in die Bedeutung geht.
Der Schreiber dieser Zeilen wünscht Ihnen viel Glück & Erfolg, erinnert aber auch gerne an die Zeiten als es noch keine dbzgl. bemühte Sprachforschung gab, als Martin Luther und andere noch “raushauen” konnten, wie es ging.
Die Eingrenzung der Sprachlichkeit [1] macht in bestimmten abgegrenzten Bereichen Sinn, also bei Dokumentationen oder technischen Dokumenten, weniger im freien Austausch.
MFG
Dr. Webbaer
[1] was wirklich gemeint ist, die Sprachlichkeit betreffend, sind Entitäten, Entitätsbeziehungen, darauf aufsetzende Konzepte oder Ideenlehren, Metaphorisches allgemein – da kommen weder die Maschine mit, sie kann nicht umfänglich folgen, noch der Linguist
Nachtragend
Da sind Sie beim G.M. richtig, dafür ist das gedacht.
Vgl. auch mit diesem Gag:
‘Im Deutschen gibt es kein generisches Maskulinum und die „generische“ Verwendung maskuliner Formen bringt keinen praktischen Vorteil mit sich.’
Texte wie Musikstücke analysieren
Tesla – so wie ich es verstanden haben – könnte ein ganzes Universum von ähnlich gelagerten Textanalysatoren und Textgeneratoren begründen, ein Universum das im Bereich der Musik bereits existiert, wo Programme Musikstücke analysieren, zusammenfassen und vergleichen können und wo sie gemeinsame Charakteristika von verschiedenen Werken eines Komponisten herausfiltern um dann Musik im selben Stil zu kreiren.
Eine für Komponisten und Musikanalysten gedachte solche Musikanalysesoftware bietet folgende Features an: “You can create a graphical summary of the music. You can locate musical patterns in unexpected contexts. And you can use MelodicMatch’s charts to compare large-scale forms.”
Im Beitrag wird aber nicht nur Tesla vorgestellt, es werden auch methodische Fragen gestellt und ein Vergleich der Situation in der Computerlinguistik mit der Situation in den Naturwissenschaften angestellt. Angesichts der Vielfalt der Forschungsaspekte und Subdisziplinen in der Computerlinguistik, die syntaktische/grammatikalische Fragen ebenso wie semantische und lerntheoretische Fragen umfasst, scheint mir aber der Vergleich mit der Situation in der Teilchenphysik und ihrem “Standardmodell” problematisch. Denn zuerst müsste man den Forschungsgegenstand/die Forschungsgegenstände der Computerlinguistik klarer definieren, ebenso klar eben wie im Standardmodell der Physik wo es um Elementarteilchen und ihren Wechselwirkungen geht.
Teilgebiete der Linguistik scheinen sowieso schon eine enge Beziehung zu naturwissenschaftlichen Fragestellungen zu haben wie z.B. die Erforschung des Spracherwerbs, die bis jetzt mit psychologischen Experimenten angegangen wurde, nun aber zunehmend auch mit Methoden aus der Neurokognition erkundet werden kann.
Persönlich finde ich den Transport von Semantik in die Sprache interessant. Ich bin nämlich davon überzeugt, dass es eine vorsprachliche semantische Ebene gibt und dann eine Art Versprachlichungsmaschine, die die gemeinte Bedeutung in Sprache umsetzt. Ich bin davon überzeugt, dass schon die höheren Säugetiere und sicher die Menschenaffen dieses Denken in einer vorsprachlichen aber sprachaffinen semantischen Ebene beherrschen und beispielsweise mit Kategorien wie Handelnder (Subjekt) oder Objekt der Handlung operieren. Mit dieser Überzeugung lehne ich damit auch die weitverbreitete Meinung ab, alles Denken sei (verstecktes) Sprechen und ich fühle mich durch Aussagen wie die von Roger Penrose (Physiker und Mathematiker) darin bestätigt, er habe schon ganze Theorien entwickelt ohne in Sprache zu denken. Auch bei Künstlern ist wohl ein nicht-sprachliches Denken ein wichtiger Teil ihres schöpferischen Prozesses.
Dieses Gebiet sollte man allerdings nicht wie ich es jetzt getan habe der Spekulation überlassen sondern mit experimentell psychologischen und mit neurokognitiven Methoden weiter erschliessen.
Da hat das Methodeninventar wohl nichts gebracht:
http://de.wikipedia.org/wiki/Voynich-Manuskript
@Stephan Fleischhauer
Ich muss da widersprechen, konnte ich durch das Methodeninventar doch zeigen, dass schon 1506 ein Verfahren beschrieben wurde, dessen Anwendung einen Text produzieren kann, der dem des Voynich-Manuskripts in so gut wie allen bisher untersuchten statistischen Kennwerten ähnelt. Ich habe das sowohl ausführlich in meiner Dissertation wie auch knapper in meinem Blog (z.B. hier – http://texperimentales.hypotheses.org/278) dargelegt und bisher dazu keinen substanziellen Protest vernommen.
Dass es der Ansatz noch nicht in die Wikipedia geschafft hat, liegt daran, dass ich meine Arbeit nicht selbst dort referenzieren wollte und sich offenbar noch kein Rezipient gefunden hat, der das übernehmen wollte. Aber vielleicht ändert sich das ja demnächst.
Pingback:DH-Kolloquium II – Clash of Concepts: Text | TEXperimenTales